Table of contents
For text
First, it must be noted that only english language is supported.
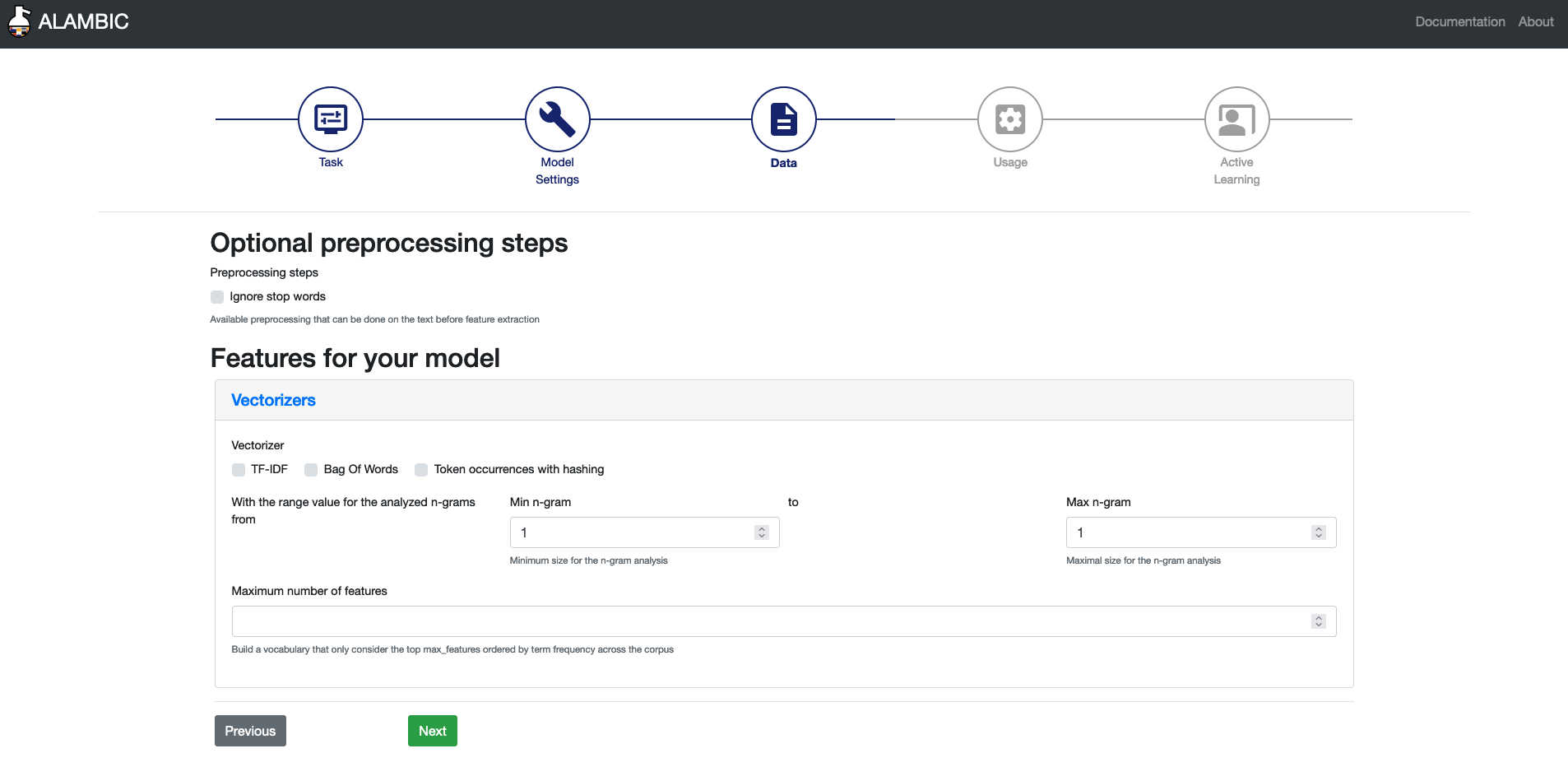
Optional preprocessing parameters
Removal of stop words
Stop words, such as “a”, “the”, “is”, are communly used words in a language. They can be removedd as they are generally considered to carry little useful information.
Required parameters
You must choose one of the methods to obtain the features which will be used by the model.
Vectorizers
Both methods are implemented with scikit-learn (see more information here)
Bag of words (or n-grams)
Each document is represented as a vector where each column represents the frequency of a specific term. Each term occurrence frequency is treated as a feature.
Term-frequency inverse document-frequency
In order to not focus on terms occurring in all documents, hence not being necessarily discriminative to describe each document, the term frequency is weighted by the inverse of this term frequency across all the documents, computed as follows :
\[idf(t)=\log\frac{1 + n}{1 + df(t)} + 1\]where \(n\) represents the number of documents and \(df(t)\) is the number of documents containing the term \(t\). The vector is then normalized with the Euclidean norm:
\[v_{norm} = \frac{v}{||v||_2} = \frac{v}{\sqrt{v{_1}^2 + v{_2}^2 + \dots + v{_n}^2}}\]Common parameters
1. Range of n-gram
The counting of occurrences can be done for groups of more than individual words (called here 1-gram). You can adjust the range of the desired grouping of words you want to explore.
For example, an n-gram range of (1,2) means the features will include individual words and bigrams, while (2,2) means only bigrams will be counted.
2. Maximum number of features
Will keep only the top max features, ordered by frequency across all documents.
For images
Coming soon